

{kind=link}
Why Ethical AI Fails Without Responsible AI
Let’s be honest for a second. The tech world is suffering from a massive case of ethical fatigue. There is a widening chasm between pristine corporate value statements and the messy, chaotic reality of software production. To survive this shift, companies have to ditch passive ethics and adopt a fiercely operationalized framework for Responsible AI.
Walk into any Silicon Valley boardroom or enterprise IT department, and you’ll find gorgeous, glossy slide decks packed with words like fairness, transparency, and human-centric design. But out in the real world? Where millions of automated decisions happen every single minute? Those decks are completely falling apart.
A real Responsible AI strategy isn’t a legal safety blanket or a marketing slogan. It’s an active engineering and governance discipline.
When organizations fail to treat it that way, they don’t just face minor bugs; they run straight into catastrophic governance failures, massive accountability gaps, deeply toxic historical bias, and silent model drift.
The screening nightmare: A 2026 case study in automated failure
To understand exactly why abstract ethics fail when scaled to millions of users, look no further than the high-stakes world of automated employee screening and background check verifications. For years, HR tech platforms promised that outsourcing talent pipelines to algorithms would eliminate human bias. Instead, it scaled it.
The real-world tech squeeze: The eightfold AI class action
In January 2026, a major class-action lawsuit (Kistler et al. v. Eightfold AI Inc.) was filed in California, targeting the massive AI hiring platform used by enterprise heavyweights like Microsoft, Morgan Stanley, and PayPal.
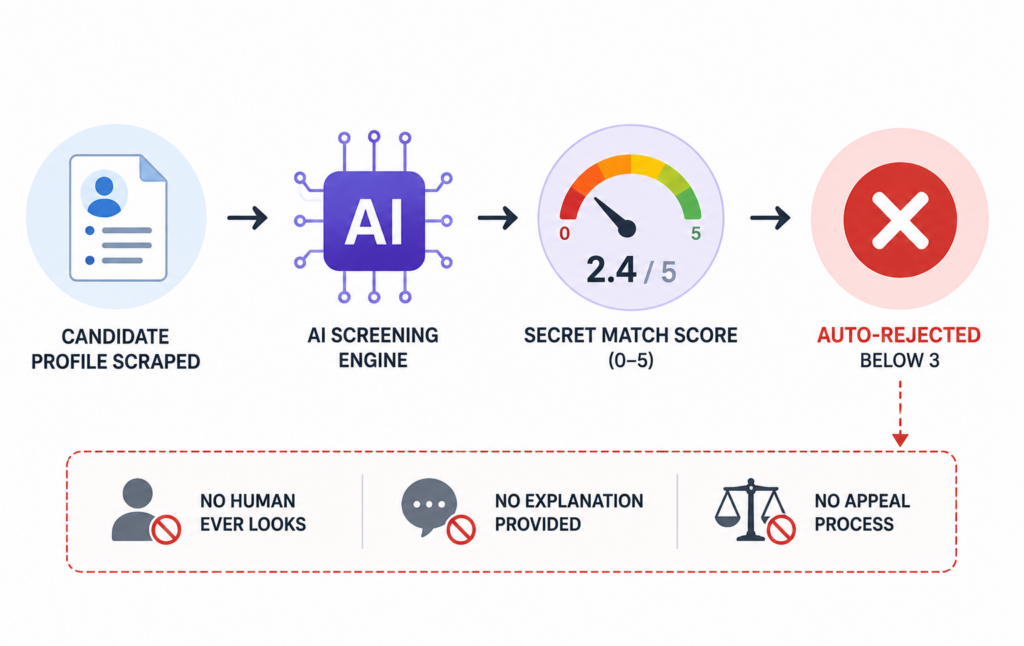
The background check and verification process here wasn’t broken because of a technical glitch. It broke because the AI was operating as a completely unmonitored black box. The lawsuit alleges that Eightfold’s platform scraped massive amounts of external data, generated secret candidate Match Scores on a 0–5 scale and automatically discarded low-ranked applicants before a human recruiter ever laid eyes on their files.
Because the system lacked an active Responsible AI framework, it created a legal and ethical disaster. The plaintiffs bypassed traditional discrimination arguments and attacked the system under the Fair Credit Reporting Act (FCRA), claiming the AI was secretly generating consumer reports without the mandatory transparency and disclosure rules. It’s the ultimate example of a company buying an efficiency tool that secretly functions as a liability engine.
The accountability gap: The algorithmic game of hot potato
Traditional software is incredibly predictable: you pass an input through a specific line of code, and you get an expected output. If it breaks, a developer fixes that exact line.
Modern machine learning doesn’t work that way. It’s probabilistic, meaning it deals in likelihoods, not certainties. When an autonomous model makes a high-stakes mistake, tracking down who is actually responsible becomes an organizational nightmare.
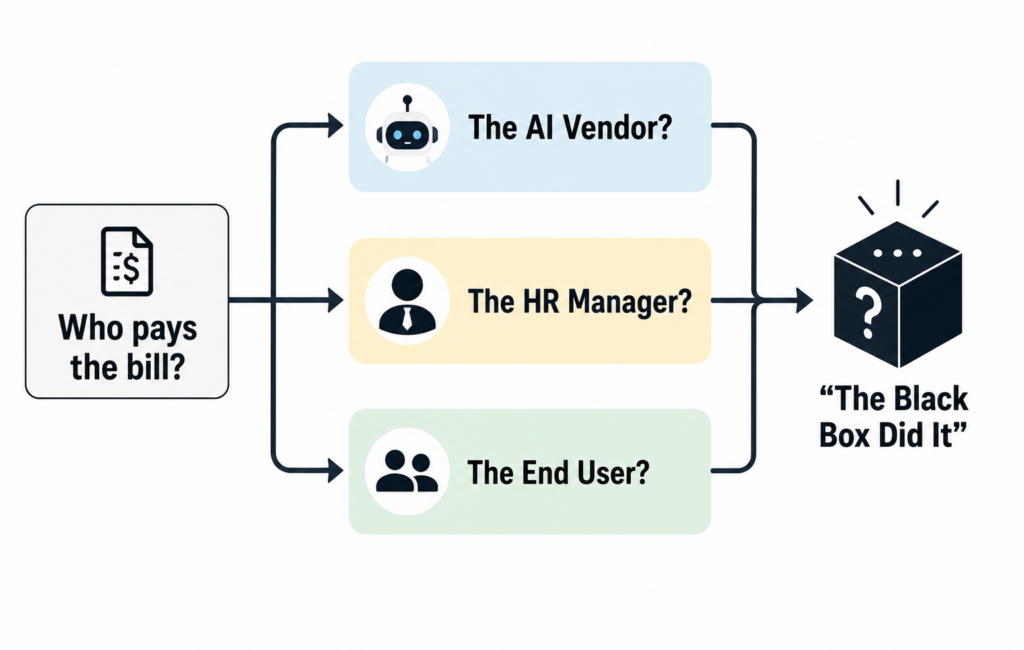
This structural reality creates a dangerous accountability gap. When a background check verification flags the wrong person or misinterprets a clean record, the vendor blames the data, the data engineers blame the user’s parameters, and the HR managers blame the software. Without a rigorous Responsible AI framework that establishes clear, un-bypassable human ownership, organizations default to treating algorithmic outcomes as infallible truths.
Bias mitigation: When the mirror is shattered
If you feed a machine learning model historical data, it doesn’t just learn how to do a task; it masterfully optimizes all the historical prejudices baked into that data.
This is the exact wall that enterprise giants have hit when trying to automate background check verifications. Take the landmark ongoing litigation against HR software giant Workday (Mobley v. Workday), which pushed past early legal hurdles in 2025 and 2026.
The lawsuit alleges that Workday’s automated screening and assessment tools created a systemic disparate impact against protected groups. How? By training models on standard, seemingly neutral data points like gaps in employment history.
To a raw, uncalibrated algorithm, a consecutive two-year gap looks like a simple negative performance risk score. But to a Responsible AI framework, that gap represents structural human realities: medical leave, disability recovery, or childcare. When a system scales to screen millions of workers globally without these human contextual guardrails, a neutral data point quickly morphs into an unchecked systemic bias.
This ends up locking qualified people out of the economy entirely, proving that data is never truly neutral.
AI drift: The silent decay of what was once safe
Let’s say your engineering team does everything right. On day one, your model is perfectly balanced, fair, and passes every compliance test with flying colors. Give it six months. Without constant intervention, that model will silently degrade through a process called AI drift.
The real world changes constantly, but a trained model remains frozen in the past. This gap creates two distinct types of breakdown:
- Data drift: The structural nature of incoming user data changes drastically (e.g., a massive influx of remote, international applicants using different documentation styles for their background check verifications).
- Concept drift: The definition of what you are measuring shifts entirely (e.g., what constitutes a “fraudulent resume” or an “AI-generated application” changes as consumers adopt new generative tools).
According to a proprietary 2026 screening report by Checkr, a staggering 82% of managers are actively worried that AI makes it too easy for candidates to misrepresent their skills, while 70% agree it is creating an entirely new era of workplace identity fraud.
If an automated verification system isn’t constantly updated via an active Responsible AI feedback loop, it will continue to score candidates using outdated metrics, completely blind to the fact that its accuracy has fallen off a cliff.
Turning philosophy into code: Moving to real governance
Intentions simply do not scale. System architecture does. If your organization keeps treating ethical AI as a philosophical discussion for HR committees and boardrooms, your automated systems will continue to fail when they hit real people.
To bridge this divide, enterprises have to take these abstract values and bake them straight into their continuous software development pipelines.
| Theoretical Idea | Real-World Failure Mode | Responsible AI Engineering Countermeasure |
|---|---|---|
| Fairness | Algorithmic screening bias against job gaps. | Continuous programmatic bias audits and demographic parity testing. |
| Transparency | Black-box “Match Scores” hidden from candidates. | Implementation of explainability frameworks (like SHAP values) to justify scores. |
| Accountability | Vendors passing the legal buck to employers. | Strict contractual vendor reviews and mandatory human-in-the-loop validation checkpoints. |
| Reliability | Deepfake identities bypassing old checks. | Integrating real-time liveness detection and automated drift monitoring. |
Distilled
The Hard Truth: If you can’t audit it, explain it, and override it with a human being, you shouldn’t be running it at scale.
Closing the chasm between production reality and our highest ethical standards requires shifting our focus completely. Stop writing unenforceable corporate manifestos. Start building automated guardrails, assigning undeniable human ownership, and operationalizing true Responsible AI deep within the code itself.
