

{kind=link}
How a Single AWS Outage Bug Cascaded Across Industries
The dependency crisis: The latest AWS outage in late October shook the digital world again. It began with what seemed like a minor technical slip. A quiet DNS (Domain Name System) automation bug inside US-EAST-1 created a fault that few noticed at first. Then the failures spread. Payments stalled. Health data streams paused. Smart home devices stopped responding. Gamers could not log in. It felt like someone pulled a thread, and the internet unravelled in slow motion.
This story is not only about downtime. It is about a deeper dependency crisis.
It shows how one unseen bug can ripple across industries. It also shows how connected our everyday lives have become. Let’s explore the event, the AWS outage impact, and the lessons companies must learn now.
A small bug with a massive blast radius
The AWS US-EAST-1 outage began with an automation problem in DNS handling. A race condition produced empty DNS responses for a key internal endpoint. Services relying on that lookup began to fail. Then dependent systems followed. The problem grew into a regional issue and then into a global disruption.
AWS engineers moved fast to diagnose, isolate, and restore services. During the incident, the AWS outage downtime stretched across several hours. Some reports suggested between fourteen and fifteen hours of instability for services tied to the region. Users watched dashboards and social feeds for updates.
AWS later released a postmortem describing the event. The report noted that automation created the unexpected failure path. It also stressed new safeguards to prevent recurrence. One line stood out for many readers: “We recognise the trust our customers place in us, and we deeply regret the impact.” The quote captured the tone of the moment. It sounded humble and serious. Customers shared it widely because it felt honest.
The AWS outage impact across fintech
Impact: The outage disrupted payment processing and banking accessibility across several major platforms. Users experienced stalled transactions and sign-in errors on services including Venmo, Monzo, Revolut, Chime, and Zelle, all of which reported service degradation during the disruption. E-commerce checkout systems using Stripe and Square also saw slowed or failed payment authorisations.
Dependency: These services rely on real-time verification, authentication lookups, fraud detection models and transaction routing hosted on AWS. Many fintech workloads operate in the US-EAST-1 region, with ledger events, API gateways and risk engines tied to DynamoDB and dependent DNS resolution paths.
Solution: Fintech firms are now moving toward multi-region deployments, redundant transaction routing, isolated identity flows and resilience testing aligned with regulatory operational continuity expectations.
Healthcare and smart homes caught in the same wave
Impact: Healthcare platforms experienced delays in data uploads and access to digital appointment systems, while smart home ecosystems saw connectivity interruptions. Cloud-connected devices such as Ring doorbells, Eight Sleep smart beds, and remote monitoring tools used by health service providers encountered outages and reduced functionality during the event.
Dependency: Both sectors rely on continuous data synchronisation, remote device control, secure login services and cloud-based alerting. Many of these functions route telemetry and video through AWS regional endpoints, making DNS disruption immediately visible to users and providers.
Solution: To reduce exposure, organisations are adopting edge caching, offline fallback modes, local operational continuity, segmented regional workloads and clear communication protocols for user-facing service updates.
Entertainment and gaming collapsed for millions
Impact: The outage affected high-traffic gaming and entertainment platforms. Login failures, matchmaking disruption and streaming instability were reported across major services including Fortnite, Roblox, Twitch, PlayStation Network, and collaboration tools such as Slack and Jira, which rely on AWS for authentication and data services.
Dependency: These platforms depend on low-latency hosting, real-time player state storage, distributed content delivery and session-based authentication. Many central systems are hosted in US-EAST-1 for scale, proximity and historical deployment, leaving them exposed when DNS or control-plane automation fails.
Solution: Studios and service providers are now investing in distributed session routing, multi-region game state replication, hybrid CDN delivery strategies and proactive service-status transparency to maintain user trust during disruption.
What made this AWS outage different?
This was not a storm or a fibre cut. It was not a data-centre power failure. It was a subtle automation error inside the DNS control path. That distinction matters.
It highlights an uncomfortable truth about cloud infrastructure. Automation increases speed and efficiency, but it also introduces new failure modes when a flaw slips through. The issue did not originate in hardware. It emerged in orchestration logic, where a race condition created cascading disruption.
Another defining factor was concentration. A large volume of global workloads still default to the US-EAST-1 region because of its maturity, service availability and historic position as the first AWS region. That means a single fault in one region can affect a significant share of global traffic. The outage demonstrated how fragile this deployment pattern can be when core services fail at the control-plane level.
It also reinforced that architectural choices, rather than raw capacity, determine resilience.
Why cascading failures occur so fast
Modern digital services rely on layered components that depend on each other. When one element fails, the effects can spread rapidly across the stack. During the AWS outage, this interconnection amplified the disruption and caused services far beyond the initial fault zone to experience instability.
Key reasons cascading failures accelerate:
- Chained service calls: applications trigger APIs, which trigger databases, which rely on DNS and control-plane services.
- Automated retry loops: when services cannot connect, they retry repeatedly, increasing traffic load and intensifying congestion.
- Hidden dependencies: many organisations are unaware of indirect links to AWS systems such as DynamoDB, IAM or internal routing layers.
- Tight coupling: systems that are not architected with isolation boundaries allow faults to propagate across services instantly.
- Shared regional concentration: when workloads sit in the same region, failure domains overlap and spread more quickly.
These factors explain how a minor automation bug evolved into a large-scale incident. The outage demonstrated that resilience depends not only on cloud provider uptime, but also on how organisations design, separate and protect their own service dependencies.
What organisations are taking away from the outage?
The outage pushed many organisations to step back and rethink how they build and run services on AWS. It was a reminder that convenience is never the same as resilience, and even the most trusted cloud environments can stumble. Three clear lessons stood out across teams who had to explain delays, restart systems and reassure customers.
Lesson 1: Reduce single-region dependency
The disruption showed the risk of relying on one region, especially US-EAST-1. Companies that had everything running there felt the impact the most. Many are now spreading critical workloads across more than one region so a single fault cannot stop their services. It marks a shift from quick deployment to thoughtful continuity planning.
Lesson 2: Understand hidden service dependencies
The outage revealed that many organisations did not realise how much of their systems depended on AWS components such as DynamoDB, DNS routing and control-plane automation. These links were invisible until they failed. As a result, teams are now tracing how their services connect, testing failovers and checking that recovery paths actually work in practice.
Lesson 3: Strengthen monitoring and communication readiness
During the incident, internal dashboards showed green even as users reported problems. That gap created confusion. Organisations are now adding external monitoring that reflects real-world performance and preparing clearer playbooks so teams know who communicates, who investigates and who decides. It helps keep responses calmer and more coordinated when outages occur.
These lessons show a change in mindset. Resilience is no longer something to add later. It has become a core part of operating in a cloud-dependent world, where outages may be rare — but never impossible.
Preparing for the next AWS outage
Outages will happen again. Cloud is complex. Scale brings surprise failure paths. But organisations can reduce impact. They can design for continuity. They can embrace resilience. They can budget for redundancy.
The next steps are clear.
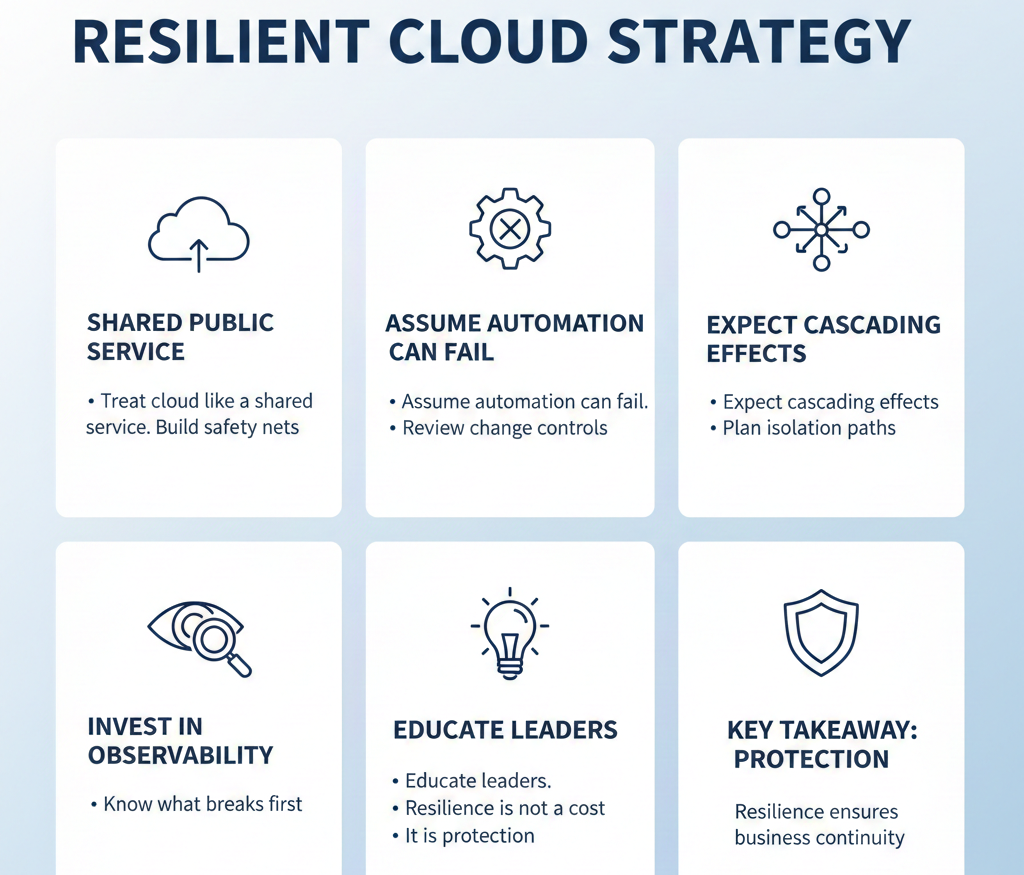
Distilled
The most recent AWS outage showed that a tiny DNS automation bug can shake entire industries. It showed how fintech, healthcare, entertainment, and smart homes all rely on the same fragile foundations. It showed that convenience hides complexity. It also showed that resilience needs urgent attention.
The lesson is simple. We cannot avoid outages. But we can soften them. We can prepare. We can design systems that bend, not break. The internet will only grow more connected. That means the stakes will rise. The smartest organisations will learn from this outage now, not after the next one.
Because the next AWS outage impact will not ask permission. It will just arrive. And the businesses that planned ahead will keep moving while others freeze.
